Cahier des charges pour la migration ArSol
Introduction
Contexte
Le Laboratoire Archéologie et Territoires (LAT) est une équipe de l’UMR CITERES. Le LAT constitue l’un des principaux pôles de recherche en archéologie métropolitaine, de la Préhistoire récente à l’Epoque Moderne. Depuis sa création en 1992, il regroupe des archéologues et des historiens autour de l’étude des relations des sociétés du passé à l’espace.
Depuis 1990, le LAT a développé ArSol : une solution informatique pour l’enregistrement et l’exploitation de données de fouilles archéologiques. ArSol concerne plus précisément les données stratigraphiques et mobilières des fouilles. ArSol est une application qui repose sur le logiciel propriétaire 4D (https://fr.4d.com).
ArSol peut s’utiliser sous plusieurs formes :
- en interne depuis le LAT
- depuis l’extérieur, sur demande, avec un accès sécurisé
- en version portable autonome
- en consultation libre depuis le site http://arsol.univ-tours.fr/
Objectifs
La version actuelle d’ArSol repose sur le logiciel propriétaire 4D. L’objectif de la future version est de reprendre les fonctionnalités aujourd’hui opérées par 4D dans un développement Open Source.
L’accent sera porté sur :
- la conformité avec les fonctionnalités actuelles
- la qualité et la maintenabilité du code produit
- le lien avec les thésaurus du domaine
- l’import et l’export de données. Sérialisation attendue en CSV et JSON
- un développement qui s'accorde le plus possible avec le web sémantique (chaque page doit disposer d'une URL permettant le référencement pour un accès direct à l'information ; utilisation d'URIs pérennes pour les vocabulaires associés - Géonames, Pactols, AAT Getty...)
La maîtrise d’ouvrage (MOA) sera assurée par les chercheurs du LAT. La maîtrise d’œuvre (MOE) sera assurée au moins en partie par les ingénieurs du LAT.
Analyse des besoins
Description du logiciel existant
Le cœur du logiciel 4D est un SGBD-R (système de gestion de base de données relationnelles). Le logiciel propose aussi des interfaces graphiques pour modifier la structure de la base de données, créer des formulaires, éditer et interroger les données. Il incorpore également un langage de programmation maison pour écrire des méthodes. Enfin il permet de déployer la base et ses formulaires de requêtes sur un serveur web.
La base de données permet de gérer les données de plusieurs sites archéologiques. Si le même modèle de données s’applique aux différents sites, tous les sites ne partagent pas les mêmes caractéristiques ni le même état d’avancement dans le recueil des données et leurs analyses. Seuls quelques uns sont accessibles depuis l'interface web actuelle.
Le logiciel propose un système de gestion des accès et des droits de lecture/écriture pour la base et pour chaque site.
Les méthodes écrites dans le langage 4D par les chercheurs du LAT constituent du code métier. Ces méthodes seront traduites en PHP par les ingénieurs de CITERES, elles seront couvertes par des tests unitaires. Le développement à venir devra s’interfacer avec ce code métier en PHP.
Le développement à venir devra reprendre de l’existant les vues de type tableau, les formulaires d’édition de données, les possibilités de passage de l’un à l’autre et l’expressivité du moteur de recherche. Plus généralement le développement devra s’inspirer de la simplicité d’utilisation de 4D lorsqu’il s’agit de visualiser, interroger ou éditer les données.
L'accès à ArSol s'effectue depuis la liste des sites :
- soit en sélectionnant tous les sites (dans une optique de recherche ou d'administration globale),
- soit en sélectionnant le site sur lequel on travaille (indispensable pour la saisie - la saisie ne devrait pas être autorisée si n'est pas sélectionné un seul site),
- soit en faisant une sélection de sites pour lesquels on souhaite confronter plusieurs données (dans une optique de recherche).
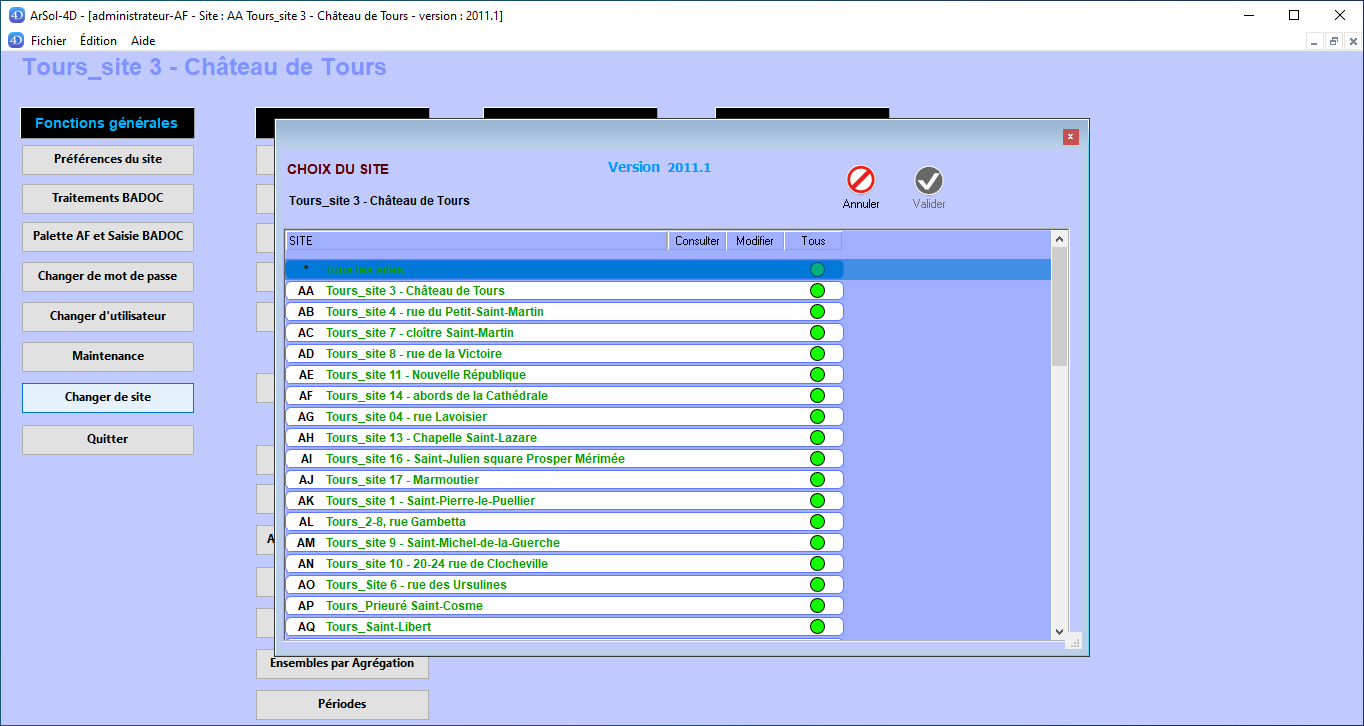 choix du site
choix du site
Le processus de visualisation/édition de données est le suivant :
-
quand l’utilisateur choisit un site il a accès à toutes ses tables
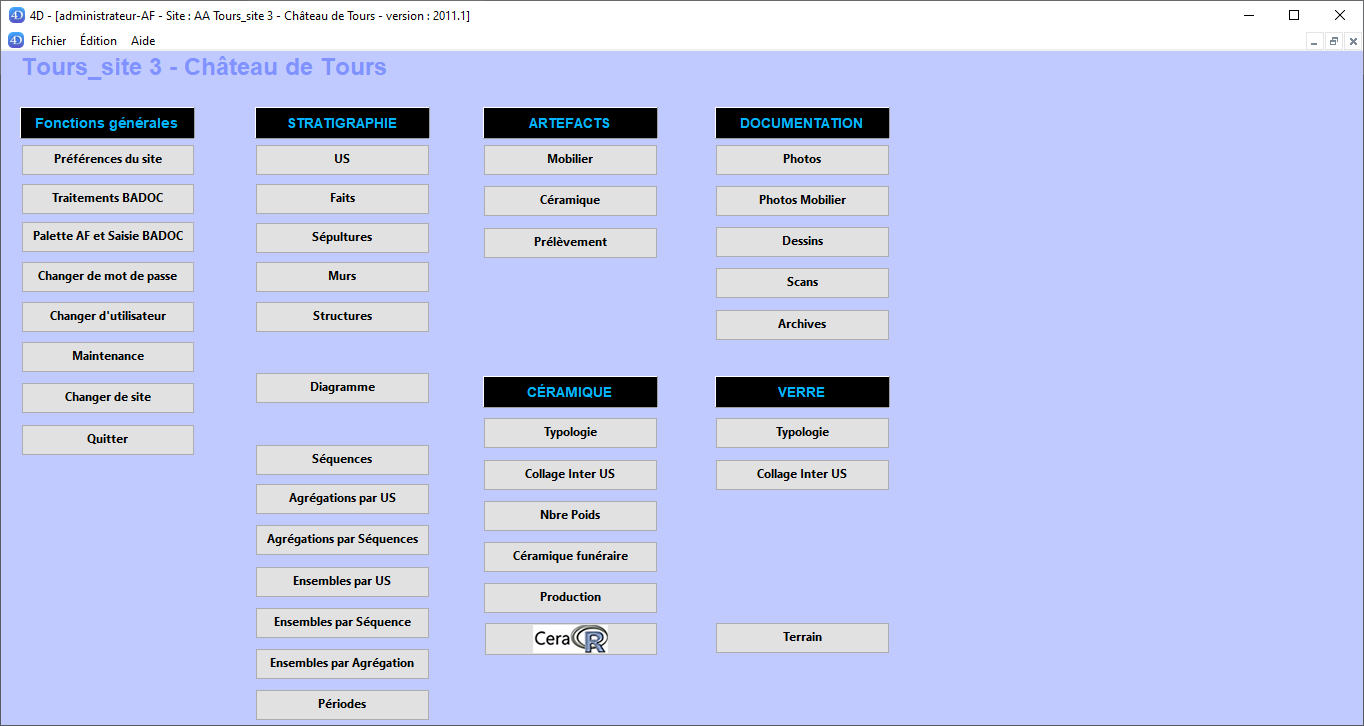 Liste des tables
Liste des tables -
quand l’utilisateur choisit une table il visualise l’intégralité des enregistrements dans une vue de type tableau.
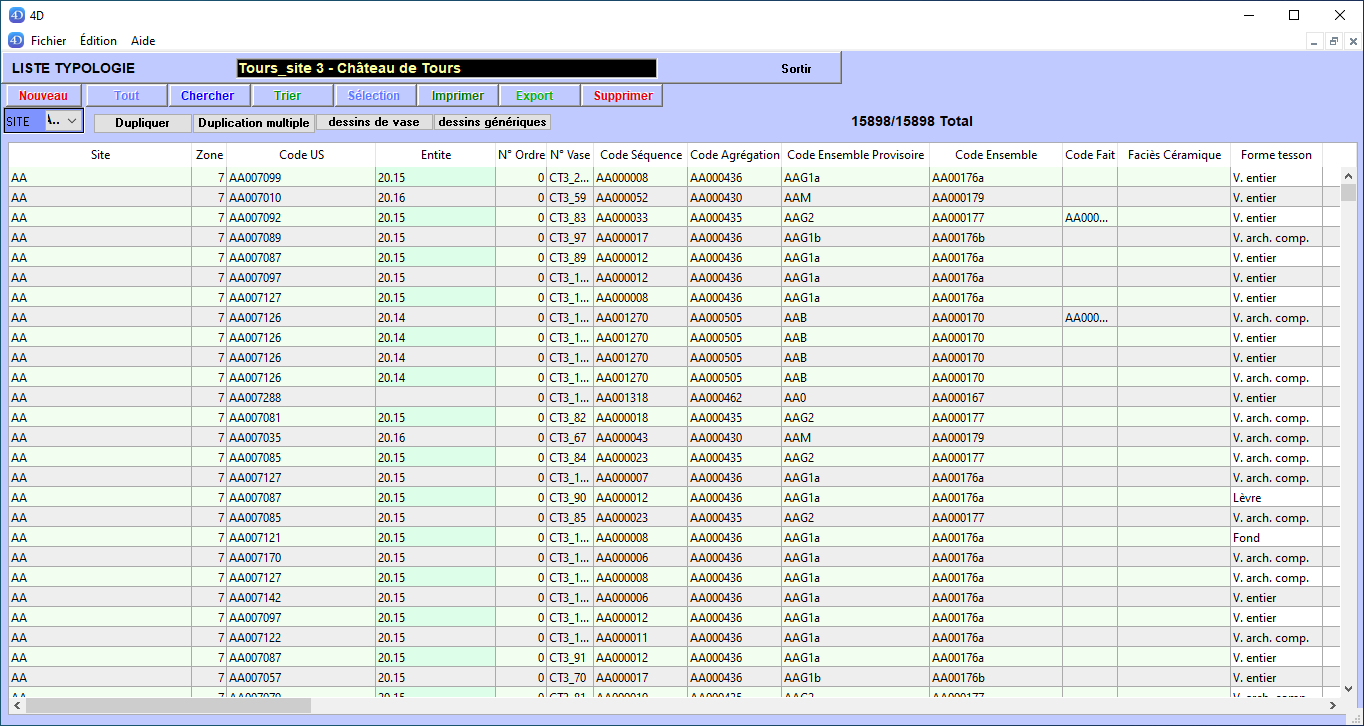 Typologie - vue tableau
Typologie - vue tableau
Les vues sont simplifiées, tous les champs ne sont pas affichés dans le tableau, mais ce tableau doit pouvoir être personnalisé. Il faudra que l’utilisateur puisse ajouter une ou plusieurs colonnes simplement. Cette vue personnalisée doit pouvoir être sauvegardée par l'utilisateur. Une réinitialisation à la vue initiale doit être possible.
Les lignes du tableau doivent pouvoir être triées et/ou filtrées par l’utilisateur (liste de choix ou recherche plein texte).
En plus des filtres et tris colonne, sont développés des outils permettant des tris complexes (sur plusieurs colonnes successivement) et des recherches complexes (sur plusieurs tables, exploitant les liens entre les tables).
- quand l’utilisateur choisit un enregistrement il accède au formulaire d’édition
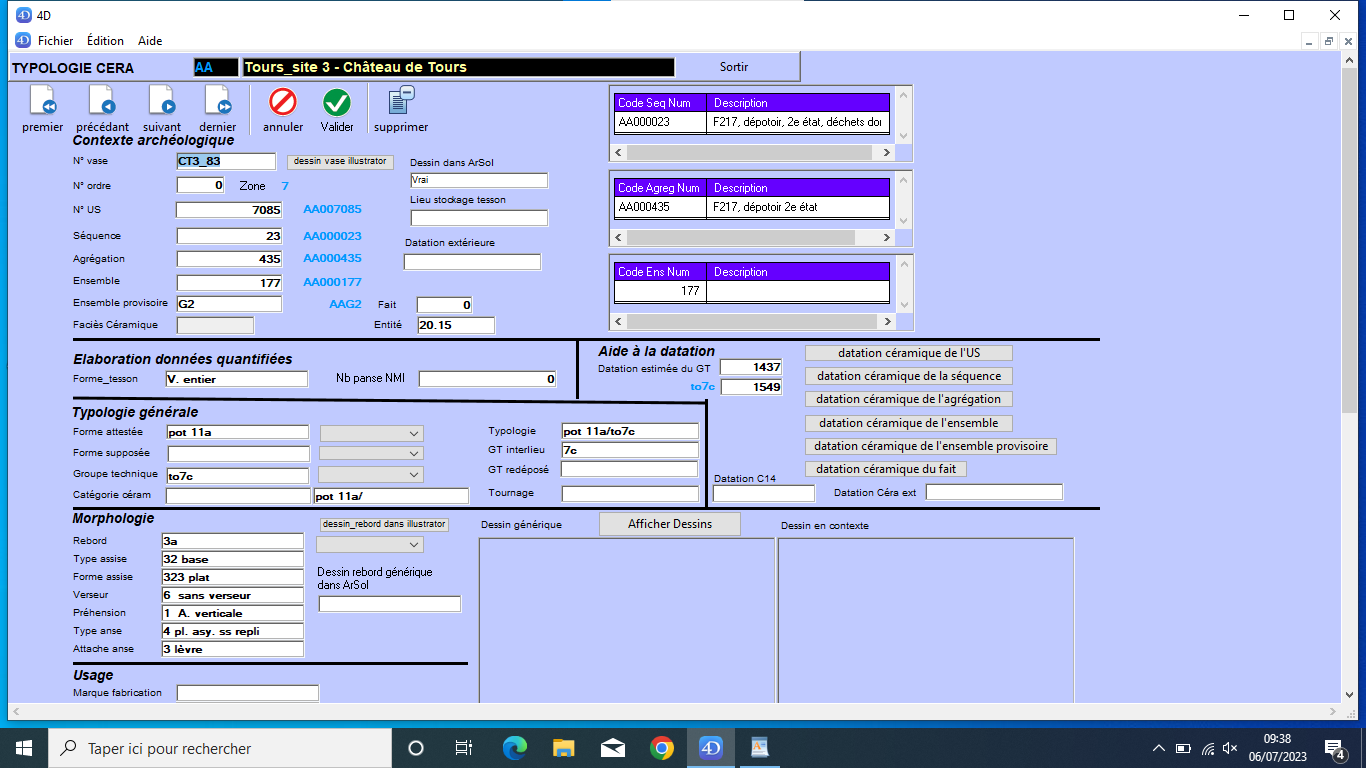 Typologie - formulaire d’édition
Typologie - formulaire d’édition
Certains champs du formulaire font appel à des vocabulaires contrôlés qui sont accessibles sans quitter la fenêtre du formulaire d’édition.
- Requêtes
L’utilisateur lance une requête à partir de la vue d’une table. La requête peut porter sur un ou plusieurs champs de la table mais aussi sur des champs d’autres tables.
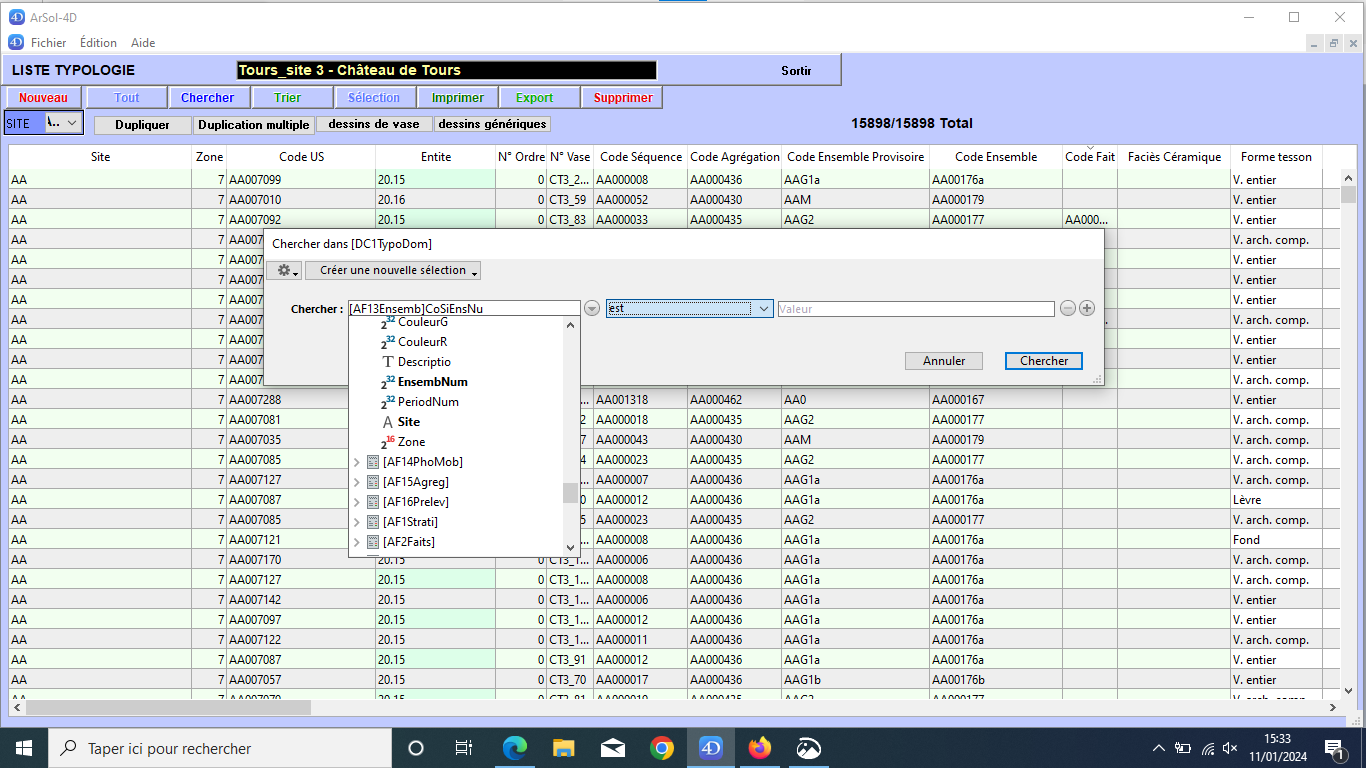 sélection du champ
sélection du champ
Le champ est comparé à une valeur, l’utilisateur peut choisir parmi plusieurs méthodes et opérateurs de comparaison.
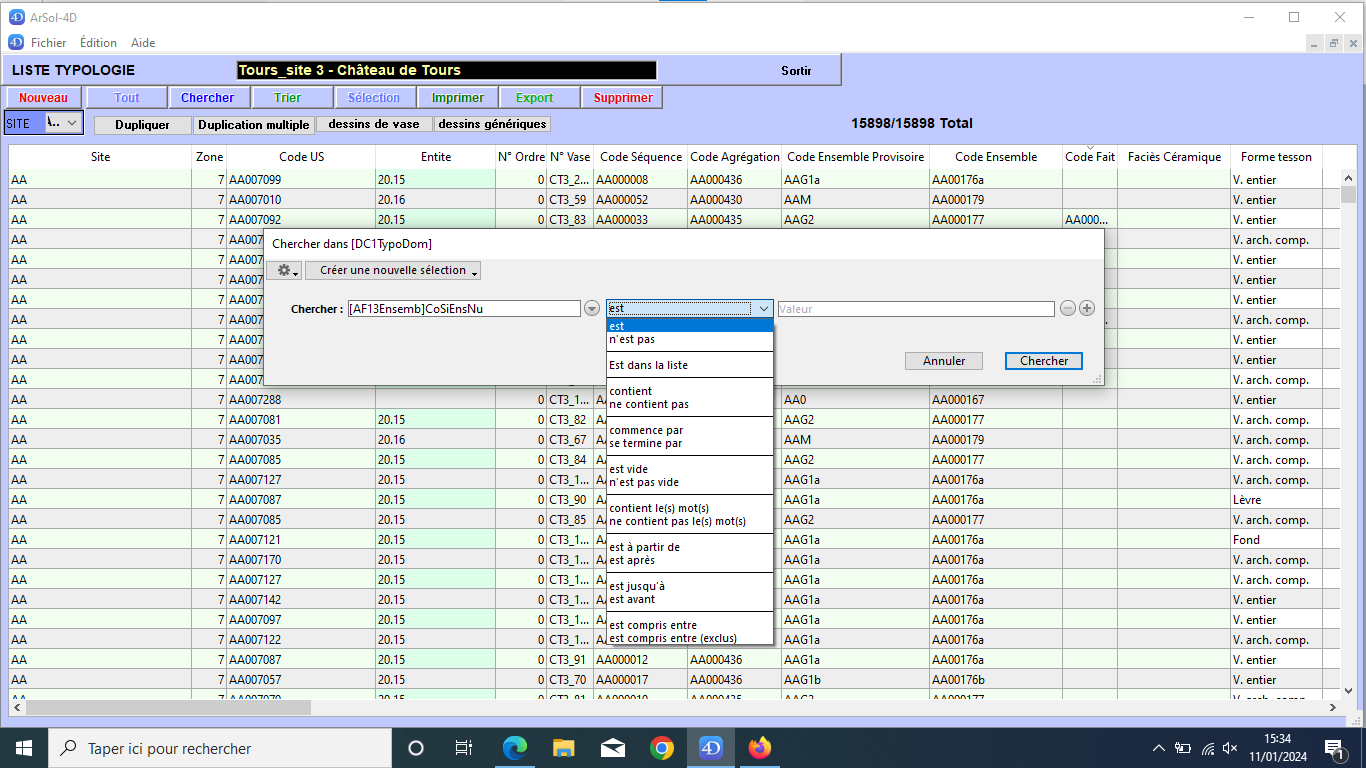 choix comparaison
choix comparaison
La requête peut porter sur plusieurs champs, l’utilisateur peut utiliser des opérateurs booléens pour composer sa requête.
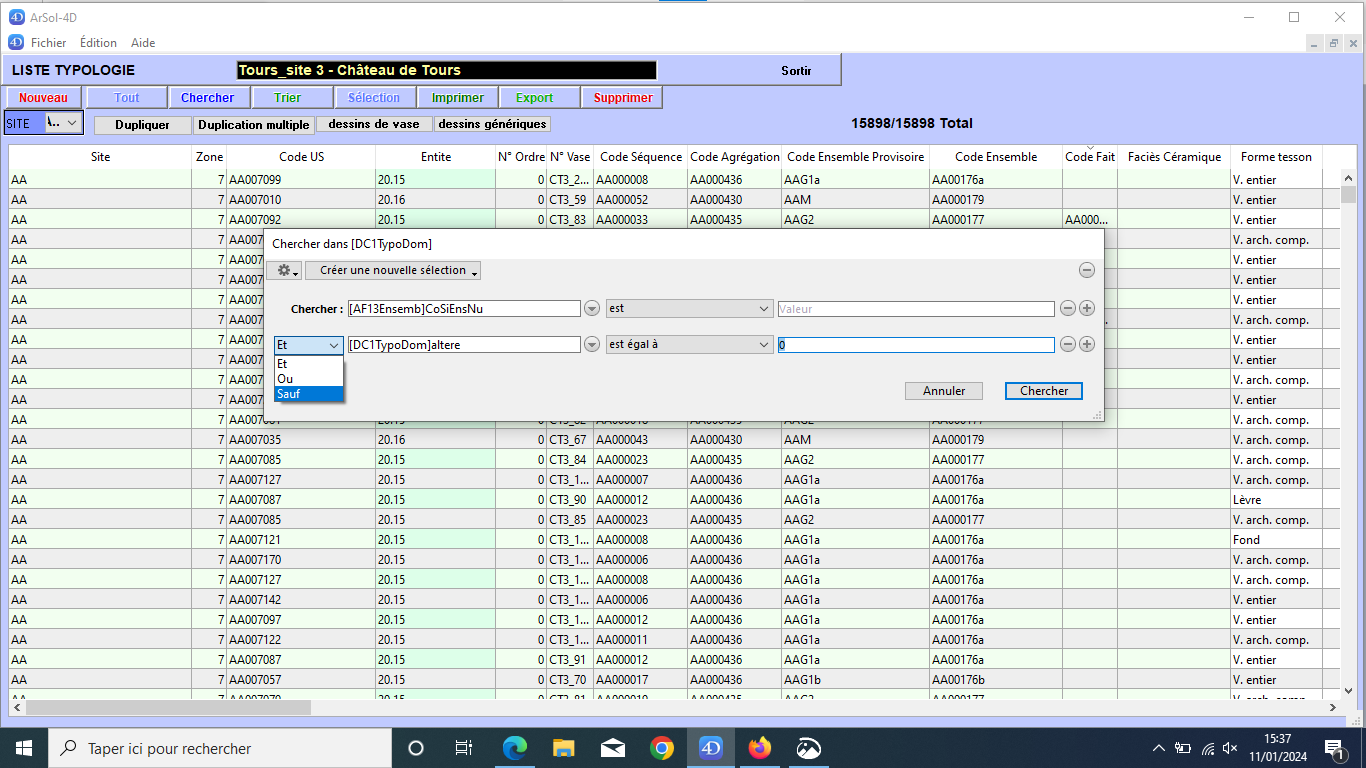 choix opérateur
choix opérateur
Attendus
Contraintes techniques
Les développements attendus constitueront une application web de type client/serveur.
Les développements attendus reposeront sur le SGBD MySQL et PHP pour le langage côté serveur.
Pour la partie base de données nous fournirons un modèle de base de données ainsi que les données existantes sous forme de dump SQL.
Le prestataire travaillera avec le framework Symfony pour la partie backend, mais avec un recours aussi limité que possible à des modules externes. Le choix de la technologie de développement sur la partie frontend se fera après l’écriture des spécifications en besoins logiciels.
L’outil développé devra être multiplateforme. Il pourra être installé et pourra fonctionner sur les OS Windows, Mac OS et Linux.
Les fouilles archéologiques sont parfois réalisées dans des lieux où la connexion internet est de mauvaise qualité. L’application web Arsol devra pouvoir être déployée et utilisée sur un poste local sans connexion internet ou avec un réseau local ad hoc. Elle devra aussi prévoir un mécanisme fiable et éprouvé de synchronisation des données après utilisation locale auprès du serveur principal.
Les développements seront sous licence ouverte.
Concernant les contraintes de sécurité, il faudra prendre en compte la réglementation RGPD pour les noms des archéologues et les propriétaires des parcelles. Les noms des propriétaires et leur localisation sont des données qui ne sont pas accessibles au public.
Description des attendus
Écriture des spécifications en besoins logiciels
La première tâche du prestataire sera de dialoguer avec les chercheurs et les ingénieurs du LAT. Il rédigera les spécifications techniques en besoins logiciels (STBL) avec les ingénieurs.
Gestion des données
Les données sont au centre du travail des chercheurs, elles seront au centre des préoccupations de la maîtrise d’ouvrage. L’application web visée pour la prestation devra assurer la persistance, l’intégrité et l’accessibilité des données. Elle devra permettre des opérations en ligne de type CRUD.
Le modèle de données sera fourni au prestataire, mais la normalisation/structuration pourra être discutée en amont des réalisations.
La base actuelle, avant remaniement, comporte 58 tables avec un total de près de 825 000 enregistrements.
Des outils de contrôle d'intégrité des relations stratigraphiques (relations sur/sous des couches) devront être mis en place, ainsi qu'un outil d'aide à la réalisation du diagramme stratigraphique (se basant sur Le Stratifiant).
Interfaces utilisateur
Les interfaces proposées aux utilisateurs ne devront pas reproduire à l’identique l’existant dans le logiciel 4D mais elles devront s’en inspirer pour les fonctionnalités, en particulier pour l’édition des données.
Certaines tables de la base comportent un grand nombre de champs. Pour ces tables il faudra proposer deux interfaces d’édition à l’utilisateur :
- une avec tous les champs
- une avec un regroupement logique des champs répartis par onglet
Les interfaces utilisateur seront de type responsive c’est-à-dire utilisables sur différents terminaux : ordinateurs et dispositifs mobiles, tablettes en particulier.
Gestion des rôles et des droits d’accès
L’application web intégrera un back-office pour l’édition des données. L’accès au back-office devra être régulé par une gestion des rôles et des droits d’accès associés aux rôles (admin, éditeur, lecteur, public). Les droits d’accès pourront être établis par site archéologique.
Utilisation de thésaurus/ontologies externes
Arsol s’inscrit dans les principes FAIR pour la Science Ouverte. À ce titre, les données saisies dans Arsol sont associées à des vocabulaires contrôlés qui devront s’apparier à des thésaurus le plus souvent externes comme Pactols par exemple. Les thésaurus et/ou ontologies sur lesquelles Arsol s’appuie disposent en général d’APIs ouvertes. Les développements visés devront faire appel à ces APIs pour lier les données d’Arsol aux thésaurus du domaine (soit dynamiquement, soit stocké en base).
Il sera nécessaire de mettre en place un tableau de bord permettant de voir les nouveaux items des vocabulaires contrôlés qui ne sont pas alignés avec les référentiels. À partir de ce tableau de bord un utilisateur avec le rôle d’administrateur web sémantique pourra aligner les termes aux référentiels.
Moteur de recherche / requêtes
La nouvelle interface doit pouvoir offrir un moteur de recherche pour accéder aux données. Ce moteur de recherche se fait à partir des tables principales, mais depuis lesquelles il est possible d'appeler des champs qui leur sont directement liés.
L'accès à ArSol se faisant par sélection de un/plusieurs/tous les sites, les requêtes seront contraintes par la sélection des sites, permettant d'interroger un seul site ou plusieurs sites.
Une requête doit pouvoir se lancer dès l'entrée ou depuis une des tables principales.
- Recherche simple texte libre dans l'ensemble de la base (comme recherche dans PHPmyAdmin).
-
Recherche avancée où l'utilisateur compose :
-
les champs en sortie
- les critères de recherche (sur plusieurs tables liées)
L'interface permettra d'exporter les résultats.
Il serait appréciable de s'inspirer de la logique du moteur Sparnatural.
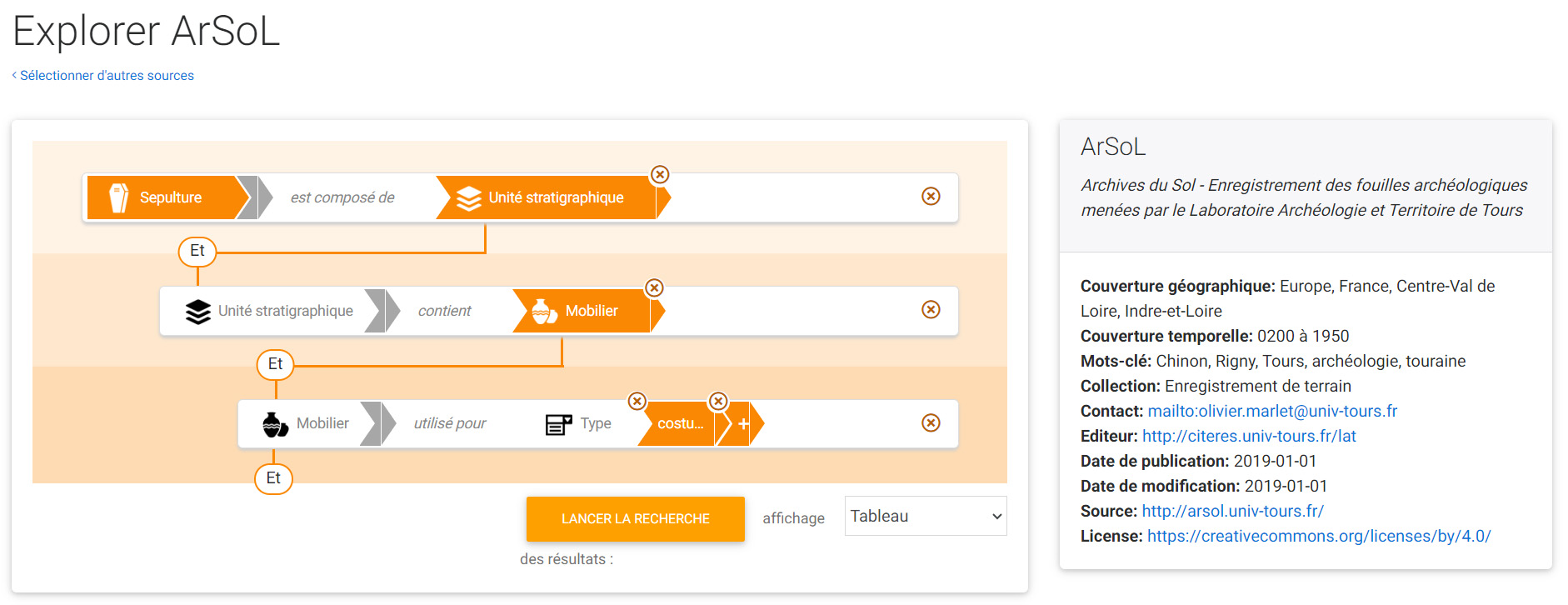 Moteur de requête JS Sparnatural
Moteur de requête JS Sparnatural
Import / Export des données CSV, JSON, SKOS-XML
Une partie des traitements sur les données est réalisée par des logiciels tiers. Arsol doit pouvoir sérialiser et exporter des données au format CSV et/ou JSON. De la même façon Arsol devra pouvoir importer des données issues de traitements externes.
Des exports seront aussi nécessaires afin d’alimenter des rapports de fouille ou d’autres bases de données (ICERAMM). Les utilisateurs devront pouvoir sérialiser et exporter chacune des tables principales ainsi que les champs liés dans les tables en relation. Le format d’export sera du CSV ou Json.
Pour le vocabulaire contrôlé, il faudra pouvoir importer et exporter les informations en SKOS-XML.
Import / Export des données d’un site
Les utilisateurs devront pouvoir exporter les données d’un site archéologique en particulier et importer ces données dans une instance d’Arsol indépendante destinée à une utilisation sur le terrain.
Suivant le contexte de la fouille cela pourra être sur un ordinateur en standalone ou en mode client/serveur sur un réseau ad hoc. Il faudra que l’application web soit en mesure de fonctionner sans accès au réseau internet.
Les données relevées lors d’une fouille d’un site archéologique depuis une instance indépendante d'ArSol devront pouvoir être synchronisées avec l’instance serveur principale d’Arsol.
Tests et validation
Le code source devra se conformer aux normes de qualité logicielle et mettra en œuvre :
- des tests unitaires
- des tests d’intégration
- Recettage
Description des livrables
- Spécification technique des besoins logiciels
- Code versionné, testé et documenté
- Documentation administrateur et utilisateur
- Procédures de mise à jour du logiciel
- Procédures d’import/export et de sauvegarde des données
- Déploiement sur l’infra de l’université et formation au déploiement
- Formation des rôles d’administrateur
Planification
Lots
- Développement d’une application web de gestion de données de fouilles archéologiques
- FAIRisation des données existantes pour être conforme avec les principes du Web sémantique
Phases
- Formalisation et spécification des besoins logiciels avec le demandeur
Temps d’échanges et de discussions entre le prestataire, le MOE et le MOA qui aboutiront à la livraison d’un document de spécification technique des besoins logiciels. - Proposition d’une solution technique par le prestataire en réponse au STBL
- Développement de la solution technique
Points techniques réguliers avec les ingénieurs du LAT
Validation des étapes de développement
Validation des interfaces graphiques avec les chercheurs du LAT - Livraison et déploiement
- Tests et recettage
Échéancier
12 mois après la signature de la prestation
Coût et modalités de paiement
Lot 1 à 105 000 €
Lot 2 à 25 000 €